

Developer Week 2025 Recap: Everything Cloudflare Just Shipped
A Full Rundown of the Announcements, Innovations, and What They Mean for Developers

The past week has been a whirlwind if you’re following the developments over at Cloudflare. For the unaware, Cloudflare has several Innovation Weeks each year focussed on a specific area of the platform.
A few weeks ago it was Security Week, and this week it was my personal favourite: Developer Week. Alongside Birthday Week later in the year, this is when we typically hear about all the latest and greatest features & products coming to Cloudflare’s Developer Platform.
This week’s Developer Week did not disappoint, and I am going to go over everything announced, explain what they are, why they are important and what you can use them for.
To give you an idea of the scale of the announcements, I will cover:
9 new products, 7 of those are available to use now
12 updates & new features to existing products
3 products & features maturing from beta to GA
We have a lot to cover, so let’s dive in.
For avoidance of doubt, this is entirely written by hand, outside of AI providing some definitions for some of the Realtime stuff
🚀 New Products
We’ll kick off the recap with all the new products announced this week. There’s something for everyone here, from Containers to VPCs to Secrets Store to Real Time and everything in-between.
Cloudflare’s Container Platform Launches in June 2025
During Cloudflare’s Birthday Week in September 2024, they surprised the world with an announcement not many were expecting: you would soon be able to run containerised workloads on Cloudflare’s global network.
In contrast to their existing offering, which is focussed on lightweight, serverless workloads, this opened the door to a whole host of new applications on Cloudflare — including applications you’re currently running on other cloud providers such as AWS and Azure.
As you can imagine, there was a lot of hype around this announcement. Containers are the go-to mechanism for packaging up applications these days, and when combined with Cloudflare’s focus on developer experience, it could really revolutionise the market.
Fast forward to this week and we got another update on containers with more implementation details, this time with a release date for the open beta: June 2025.
So what are containers going to look like on Cloudflare? Well, for the most part, much like how you use the rest of the platform. The interface is exactly the same as a Durable Object (more on that later):
import { Container } from "cloudflare:workers";
// create a new ID for a container
const id = env.CODE_EXECUTOR.idFromName(sessionId);
const sandbox = env.CODE_EXECUTOR.get(id);
// execute a request on the container
return sandbox.fetch("/some-endpoint");
// define your container using the Container class
export class CodeExecutor extends Container {
defaultPort = 8080;
sleepAfter = "1m";
}When the container receives its first fetch request, it will boot up and handle that request. It will then stay alive for as long as you configure in your class that extends Container.
Much like Cloudflare Workers, the container will be spun up as close to where the request originates as possible — reducing latency between your Workers and any containers.
Anyone who has worked with containers before knows that you need a set of instructions on how to build the container, with the most common being Docker and a Dockerfile.
That’s exactly how it will work on Cloudflare, with any OCI compatible container image supported. You simply run wrangler deploy , and Cloudflare will build and push your container image to their registry, ready to be used by your application.
Now, you might be thinking: what about cold starts? Well, depending how you configure your containers, you may experience cold starts while the container boots.
However, there is configuration available to set a minimum number of instances — this means Cloudflare pre-warms your containers so they are ready to serve requests immediately. Alongside prewarming, you can also set a CPU threshold that will define when your containers scale up to meet demand — meaning autoscaling is built-in to the platform.
Earlier I mentioned that the interface was that of a Durable Object, so it might not surprise you to hear that each container instance has a companion Durable Object. In essence, the Durable Object is acting as a sidecar, allowing you to communicate with and manage its companion container.
For example, from the Durable Object, you can:
Start a container
Stop a container
Execute a bash script
Define callbacks for some events (e.g. container stops, container errors)
Allow WebSocket connections to your container
Before moving on, let’s touch on pricing quickly, with these costs being currently advertised:
Memory: $0.0000025 per GB-second
CPU: $0.000020 per vCPU-second
Disk $0.00000007 per GB-second
Unlike the rest of the Cloudflare platform, there will be charges for egress. You’ll get 1TB of transfer for free every month, and then the pricing after that is TBC.
Enjoying the article and want to get a head start developing with Cloudflare? I’ve published a book, Serverless Apps on Cloudflare, that introduces you to all of the platform’s key offerings by guiding you through building a series of applications on Cloudflare.
Buy now: eBook | Paperback
Global Virtual Private Clouds Available Later This Year
On the face of it, the announcement of VPCs might not seem the most exciting thing ever.
However, I’ve had countless conversations with companies, small and large, that want to use Cloudflare’s Developer Platform and they simply can’t — because their AWS resources, for example, are within a VPC that Cloudflare Workers cannot securely connect to.
You can expose your resources running in an AWS VPC to the wider internet, but if it’s an internal application, you’re then exposing your internal application simply to connect it to Cloudflare — which is far from ideal. You could also toy around with Cloudflare Tunnels and Zero Trust, but that’s a lot of work, and has to be done for each application.
In terms of connecting from a Cloudflare Worker to a private API in an external VPC, it will be handled using a new binding:
const response = await env.WORKERS_VPC_RESOURCE.fetch(“/api/users/342”)Likewise, you can connect from an external VPC to a Workers VPC using standardised URL patterns (e.g. https://<account_id>.r2.cloudflarestorage.com.cloudflare-workers-vpc.com).
Along a similar vein, at present, your Workers on Cloudflare all run globally — there are no VPCs. With the introduction of Workers VPC though, you can now segment your Workers into VPCs, significantly improving security.
That means you can, if you wish, segment different applications into their own VPCs — prevent access to its internal data stored on services such as R2 from other systems.
If you’re keen to get your hands on the new VPC functionality, you’ll have to wait for more news later in the year, when I suspect it will be available in some form of beta.
Simplifying RAG Pipelines with AutoRAG
If you’ve ever worked on a RAG pipeline, you’ll know what a nightmare it is to setup. I actually spoke about this exact problem at Cloudflare Connect in London this week — as I’ve worked with RAG a lot in my day job.
On the face of it, you just need some documents, some embeddings and a vector database, right?
Well, if only it were that simple. What if your source documents are 100’s of pages long? You need to chunk them, and likely ensure there are overlaps between the chunks. What if your source documents are in a variety of formats? You need a parser for each one, potentially including image recognition if you have images. That’s just the initial ingestion, what about ensuring your source documents stay in sync with your data stores in an efficient manner, and ensuring deleted documents are removed from your vector database?
I could go on, but you get the idea. The asynchronous aspect of RAG, managing the underlying data, is surprisingly complex — and not something you want to build yourself.
Luckily for you and I, Cloudflare has released AutoRAG in beta, providing everything need to get started with adding RAG to your application. On the ingestion side, it handles:
Chunking
Parsing
Indexing
Storage
Retrieval
LLM Generation
All that’s required from your side is an R2 bucket containing the information you want to be available to your LLM, and AutoRAG will handle the rest — including keeping all the data in sync and re-indexing when needed.
Under the hood, AutoRAG uses R2, Vectorize and Workers AI in combination to provide that RAG pipeline.
On the application side, you can either opt to retrieve the raw chunks via AutoRAG and manually call an LLM with that context, or you can have AutoRAG call an LLM for you as part of a single call and pass the retrieved context automatically.
At present, only Workers AI models are available for embedding and LLM generation, so if you want to use OpenAI or Anthropic models, you’ll just want to make use of the retrieval aspect for now.
Keep in mind, as with all the products that are heading into beta, that they are just that — a beta, an early look, and not the finished products. You’ll likely experience low limits (such as 1MB max file sizes for AutoRAG) and some errors here and there — but these things will be ironed out before each product graduates to being generally available (GA).
I’ve actually tried this one out already, and I managed to implement RAG into an existing AI-powered application in literally 15 minutes, as AutoRAG just does so much of the heavy lifting.
In terms of pricing, it’s not explicitly mentioned in the article, but my assumption would be you’ll just pay for the underlying resources you use from R2, Vectorize and Workers AI, with no costs for using AutoRAG itself — but that’s just my intuition, rather than an official line.
Managed Apache Iceberg Tables with R2 Catalog
Switching gears a little, and moving over the data side of the application lifecycle, we have what could be a significant entry in the data warehouse space.
You could argue this is adding a feature to R2 versus a new product, but I think it’s a completely different use case being unlocked, so I granted it a space in this section.
If you’ve ever seen your company’s bill for the data storage used to provide data to the likes of Snowflake, AWS Redshift and Databricks, you’ll be surprised how expensive it can be.
Last year, AWS announced S3 Tables which also provide Iceberg capabilities on top of S3 — the first time cloud object storage had been able to do this, and now Cloudflare has entered the game with their offering.
This isn’t my area of expertise, so rather than attempt to explain, I’ll let Cloudflare explain with this excerpt from their article:
If you’re not already familiar with it, Iceberg is an open table format built for large-scale analytics on datasets stored in object storage. With R2 Data Catalog, you get the database-like capabilities Iceberg is known for — ACID transactions, schema evolution, and efficient querying — without the overhead of managing your own external catalog.
R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect the engines you already use, like PyIceberg, Snowflake, and Spark. And, as always with R2, there are no egress fees, meaning that no matter which cloud or region your data is consumed from, you won’t have to worry about growing data transfer costs.
One thing that did immediately strike me was how much more cost-effective this will be than most other solutions, thanks to R2’s zero egress fees. If you’re using S3 currently, which does charge for egress, you could save a pretty penny by switching to R2.
On the Cloudflare side, opting your R2 bucket into being a data catalog is a one-liner with Wrangler (or use the dashboard):
npx wrangler r2 bucket catalog enable my-bucketOnce that’s complete, you can then connect using whatever mechanism you typically use — such as PyIceberg and PyArrow.
R2 Data Catalog is in open beta, and free while in open beta too. The pricing for the R2 buckets themselves remains the same as R2 today, with some additional charges (once the beta period ends) for the data catalog feature. Here’s their current thinking on pricing, but this is TBC:

During the beta period, Cloudflare will be looking at improving the performance of R2’s Data Catalog with compaction and table optimisations, alongside expanding query-engine compatibility with the Iceberg REST Catalog spec.
Simplify Secret Management with Secrets Store
If you’ve ever used Cloudflare Workers, you’ll know that secrets are set on a per-project basis. They can either be plaintext or encrypted, but critically, they cannot be shared between projects.
If you have a lot of Workers — and some people have a serious number of Workers — and you need a secret across a number of Workers, it becomes a management nightmare. Let’s say you need to rotate an API key across 100 Workers — that’s going to be a lot of manual work, not to mention prone to human error.
Furthermore, anyone who can modify a Worker could also modify the secrets — potentially causing outages but also not respecting good security practises, where people should have as little access as they need.
This has been the state of play for quite some time, but with Secrets Store, these two problems will be no more. First announced in mid 2023, Secrets Store, as the name suggests, will allow you to create centralised stores for your secrets.
These can then be shared across Workers via bindings, meaning if you need to rotate a secret, you can do so seamlessly across all your Workers.
Additionally, Secrets Store brings RBAC into the fold, with three roles to provide fine-grained access to secrets store based on the needs of each user in your organisation

This means the ability to create, update and delete secrets can be restricted to a few people — rather than your entire engineering team. You can also scope each secret to a given product, to further enhance security. For now, there’s only Workers, but in future I suspect it will extend to the Container platform and Snippets, as two likely candidates.
Accessing a secret is nice and simple:
const openAIkey = await env.open_AI_key.get();This does mean there is a latency hit for using Secrets Store, as I suspect it will need to make a network request — but hopefully this is minimal, and in future, hopefully it’s possible to inject secrets directly into a Worker at runtime, in the same way it works today.
During the beta, you can create up to 20 secrets for free, with pricing for more keys to be announced at a later date — I suspect when Secrets Store goes GA.
Workers Observability Launches with Logs, Metrics & Queries
If you cast your mind back a year ago, observability on Cloudflare was sorely missing. There were real-time logs, that weren’t persisted anywhere on the Cloudflare platform, or you could push them to an external provider (which is typically quite expensive).
That made debugging exceptionally difficult. That’s why a year ago, during Developer Week, Cloudflare announced the acquisition of Baselime — an observability platform focussed on serverless platforms.
After meeting the guys behind Baselime at a conference, I actually hooked all my Workers up to their platform so I could observe my Workers — all before the acquisition.
Since then, the same team has been working on bringing observability to Cloudflare as a first-class citizen — with Workers Logs being released in beta a few months later at Birthday Week in 2024.
This week, we got to see the next evolution of Cloudflare’s observability journey, which included three drops:
Workers Metrics Dashboard (Beta): A single dashboard to view metrics and logs from all of your Workers
Query Builder (Beta): Construct structured queries to explore your logs, extract metrics from logs, create graphical and tabular visualizations, and save queries for faster future investigations.
Workers Logs: Now Generally Available, with a public API and improved invocation-based grouping.
Until this week, you could only see logs for an individual Worker at a time. Thanks to the new observability dashboard, you can see an aggregated view of all your logs across your Cloudflare Workers.
To make this aggregated view more powerful, a query builder has been added to allow you to comb through your logs and find what you need. You get everything you’d typically expect with a query builder for logs including visualisations (count, sum etc.), filters, search, group by and more.
Another really nice improvement is the ability to see the CPU and wall time of your Workers, which is also queryable. And lastly, you can view logs on a per-invocation basis. For example, you may want to dive into all the logs for a given invocation to see what happened — you can do that now.
Streaming Ingestion with Pipelines
Stick with me — we’re almost there for new products, with 3 to go.
Moving onto another product that was announced last Developer Week, we have Pipelines entering open beta (restricted to Workers Paid, $5/month). Using Pipelines, you’re able to ingest large volumes of data (100MB/s, I believe) using Cloudflare, and they’ll push it all to the R2 bucket you specify.
Imagine you need to ingest clickstream data from all your customers, where you may have a significant number of concurrent users on your site — each click, page navigation and action is recorded from every device. This can generate a large amount of data, and ingesting it can be tricky — but not with Pipelines.
You don’t need to worry about any of the underlying infrastructure, you simply create a Pipeline and link it to an R2 bucket:
npx wrangler pipelines create my-clickstream-pipeline --r2-bucket my-bucketAnd that will give you a URL which you can fire your data at, it’s as simple as that.
Now, the chances are you probably want to do something with that data — not just let it sit on R2. Maybe you want to transform it, maybe you want to load it into another system for analysis.
Either way, Cloudflare has acquired Arroyo to make that a reality — with Arroyo’s offerings being brought into the Cloudflare estate. They are not available today, but will be in the future.
There’s cohesion with this announcement and the R2 Data Catalog too, as in the future you’ll be able to ingest the data straight into an R2 bucket with Data Catalog enabled, and then be able to immediately query that data.
In terms of what’s next, besides transformations, there’s integrating Workers as UDFs (User-Defined Functions), adding new sources like Kafka clients, and extending Pipelines with new sinks (beyond R2).
If you’re curious about pricing, there is no cost for Pipelines during the beta, but you will pay the R2 costs. Beyond beta, this is the proposed pricing:
Ingestion: First 50 GB per month included in Workers Paid, $0.02 per additional GB
Delivery to R2: First 50 GB per month included in Workers Paid, $0.02 per additional GB
With Cloudflare making more and more products available on the free plan, you’ll also be pleased to hear that will happen as the beta progresses.
Introducing RealtimeKit: Realtime Audio & Video Experiences
Onto our penultimate new product, and it’s something quite different again to anything we’ve seen so far in this recap. I think it speaks to the depth and breadth of Cloudflare’s offering, and how much it’s grown recently.
So what exactly is Realtime? In short, it’s a suite of products to help you integrate real-time audio and video into your applications. Cloudflare Realtime brings together their SFU, STUN, and TURN services, along with a new RealtimeKit SDK.
That’s a lot of acronyms, so what exactly are they?
SFU (Selective Forwarding Unit) routes media streams between participants without decoding them, STUN (Session Traversal Utilities for NAT) helps devices discover their public IP addresses for peer-to-peer connectivity, and TURN (Traversal Using Relays around NAT) relays media through a server when direct peer-to-peer connections fail due to strict NAT or firewall settings.
In essence, it’s complicated infrastructure that is required for these real-time use cases, and setting them up yourself would be difficult and a maintenance nightmare. With Cloudflare’s offering, you can let them handle all the infrastructure, and you just plug them into your applications as-needed.
Speaking of plugging into your applications, there’s also an SDK available to make integrating these things easier. Interestingly, it’s only available in closed beta, with the sign up form here.
The SDK is quite vast, containing mobile SDKs (iOS, Android, React Native, Flutter), SDKs for the Web (React, Angular, vanilla JS, WebComponents), and server side services (recording, coordination, transcription).
I’ve never had to implement such things myself, but if I did, I’d absolutely give Realtime a go as it seems to do so much heavy lifting for me. There’s a ton of technical detail and further explanations in the announcement post, which I highly recommend giving a read.
Deploy to Cloudflare from any GitHub/GitLab Repo
Onto the last one, and this one is small but mighty. Getting people to use your platform can be tricky — especially when the bigger players have a significant moat and head start on your.
Therefore, it’s critical to make it as easy as possible for people to try out your platform, removing as many barriers to entry as possible.
That’s why I like the new deploy to Cloudflare button, that’s available for anyone to use now in GitHub and GitLab. With one line of Markdown, you can add this button to your repository, and anyone can deploy your Worker to Cloudflare instantly.
Once clicked, it will do the following:
Creates a new Git repository on your GitHub/ GitLab account
Automatically provisions resources the app needs (including dependent resources like R2, D1 etc.)
Configures Workers Builds (CI/CD)
Adds preview URLs to each pull request
There isn’t much more to say around this one, it’s definitely a nice quality of life update, and certainly beats following a set of instructions in a README.
💎 Major Product Updates
Are you still with me? I know, that was a lot. If you made it this far, thank you, and let me repay you with yet more content drops across a range of existing Cloudflare products & services.
In this section, we have everything from AI to Static Assets to Workflows to Hyperdrive to Durable Objects and much, much more. We’ve got a lot to cover, so let’s get going!
Agents SDK — Remote MCP & Auth
It wouldn’t be a Developer Week recap without plenty of AI, and we’re kicking it off with some AI-focussed updates to kick things off.
Earlier this year, Cloudflare released the Agents SDK to make building AI agents easier — backed by the power of the Cloudflare platform.
The SDK can be used not only to make AI Agents, but also remote MCP servers. Companies such as PayPal have already used this exact SDK to deploy their own MCP server, just to show you how quickly MCP and this SDK is growing in popularity.
However, until this week, you couldn’t power-up your AI agents by giving them the ability to connect to remote MCP servers. But good news — now you can, with the new MCPClientManager class.
Better yet, this class handles everything you need to manage the lifecycle of connecting to remote MCP servers, including transport, connection management, capability discovery, real-time updates, namespacing and authentication (via Stytch, Auth0, and WorkOS).
While the focus was on enabling AI agents to connect to remote MCP servers, there was a nice quality of life update to MCP servers built on Cloudflare too — they are now able to hibernate between requests, making them significantly cheaper to run. This is thanks to the power of Durable Objects, which are able to hibernate when not handling any requests.
If you’re curious what agent capabilities you can build with this SDK, I highly recommend checking out agents.cloudflare.com — not only does it do a great job of highlighting AI use cases and ways to solve them, it’s incredibly jazzy too.
Workers AI — quicker, batch support, new models, LoRA & New Dash
Continuing the AI theme, we’re onto Workers AI — Cloudflare’s global inference platform for AI workloads. This means your inference tasks run significantly closer to the end user than other platforms, with Cloudflare having GPUs in close to 200 cities worldwide.
This platform is now 2–4x quicker, thanks to a series of improvements involving speculative decoding, prefix caching, an updated inference backend, and more.
Wondering what those fancy-sounding things are? Me too, so I asked ChatGPT to summarise them in a sentence:
Speculative decoding in LLMs accelerates text generation by having a smaller, faster model predict possible continuations that a larger model then verifies, while prefix caching reuses previously computed hidden states to avoid redundant calculations when generating text from shared prompts.
Well, that clears that up nicely — and to ensure there was no impact to the quality of the responses, there was extensive A/B testing before this has been applied. For now, it’s only applied to cf/meta/llama-3.3–70b-instruct-fp8-fast, but presumably will be rolled out wider over time.
Moving onto another topic, let’s talk about batch processing. Until this week, you could only synchronous call models hosted on Workers AI — even if you didn’t have an immediate need for the response, or needed all responses to be returned before you processed them.
Now however, you can pass an additional parameter when calling Workers AI, and it will queue the request rather than return immediately. You can then poll for the response via API or the AI binding.
In terms of why you might use this piece of functionality, consider that sometimes GPUs get overloaded and can’t handle your response — or take a long time to do so. If you don’t immediately need a response, it’ll be better to schedule it via the batch functionality, which will handle retries automatically.
Switching topic one again, we’re onto LoRAs — which are now available on more models.
In essence, a Low Rank Adaptation (LoRA) adapter allows people to take a trained adapter file and use it in conjunction with a model to alter the response of a model. Think of it like a cheaper alternative to fine-tuning, where you can make a model more suited to your use case.
LoRA support is/will be available for the following models:
@cf/google/gemma-3–12b-it (soon)
While we’re talking about models, there are some new brand ones too (and I stole the descriptions from the blog post rather than rehashing them):
@cf/mistralai/mistral-small-3.1–24b-instruct: a 24B parameter model achieving state-of-the-art capabilities comparable to larger models, with support for vision and tool calling.
@cf/google/gemma-3–12b-it: well-suited for a variety of text generation and image understanding tasks, including question answering, summarization and reasoning, with a 128K context window, and multilingual support in over 140 languages.
@cf/qwen/qwq-32b: a medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.
@cf/qwen/qwen2.5-coder-32b-instruct: the current state-of-the-art open-source code LLM, with its coding abilities matching those of GPT-4o.
One last thing for Workers AI before we move on: there is a shiny new dashboard to help you understand your AI workloads that shows your usage in traditional measurements (tokens, seconds) versus the Neurons that Cloudflare has been using — I really like this one as it makes it a lot easier to reason about your usage, as people are used to using tokens, for example.
Durable Objects — Available in the Free Tier
I cannot understate how excited I am for this announcement. For as long as Durable Objects have existed, they have been gated behind the Workers Paid plan. By no means a large barrier to entry, but if you simply wanted to try them out, $5 was probably going to put you off.
With Durable Objects underpinning the Agents SDK, and being very unique and magical, you won’t find anything like these anywhere else, it’s a no-brainer to make them available on the free plan.
For the uninitiated, Durable Objects are effectively defined in your code as normal-looking classes. However, they are far from normal, as at runtime you’re able to spin up effectively unlimited instances of these classes — but the twist is they are not instantiated in the same process as the calling code, it spins up a remote server where the code is executed.
You can spin up as many of these as you need on-demand, with some Cloudflare customers having millions of instances of Durable Objects. Each instance is unique, and there can only ever be one instance with a given ID active at any one time globally, making them perfect for multiplayer and coordination.
They come packed with features too, including:
Durable storage (Key-value, SQLite) — they hibernate between requests, but their storage remains intact between restarts.
WebSockets built-in — you can genuinely connect via WebSockets in a few lines of code, and they hibernate between WebSocket messages, making them incredibly cost-efficient.
Alarms, to handle scheduled tasks
The ability to make RPC calls to a Durable Object from other Cloudflare products such as Workers
At first, it can be hard to get your head around Durable Objects, or even explain them to anyone. But, I highly recommend you give them a try, as they are incredibly powerful. And as you just learned, they are now available to try for free. The free plan is pretty generous too:
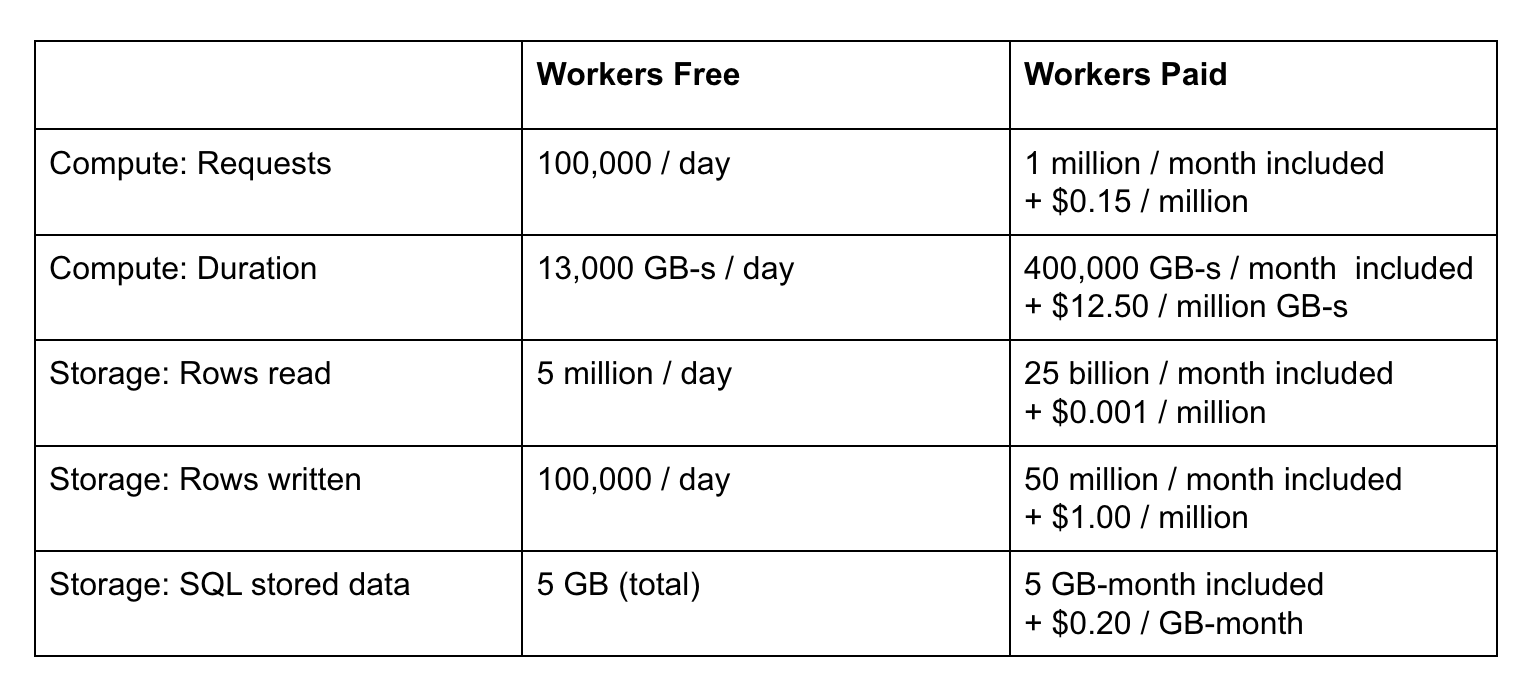
[full article] (part of the Agent MCP post, but I felt like it deserves its own!)
D1 — Support for Global Read Replication
Moving away from AI and onto databases — we’ll cover D1 first, and then take a look at what’s new with Hyperdrive.
If you’ve not heard of D1 before, it’s Cloudflare’s SQLite offering. Well, technically, they have two, as I just explained that Durable Objects have SQLite capabilities too!
When to use each is a topic in its own right, but considering D1 now has read replicas globally, the quick answer is use D1 when you need that global availability. As a Durable Object exists in one location, you may experience high latency when making calls from the other side of the world, at least when compared to D1.
Winding back a little, D1 has been around for quite a while now, with its beta landing in September 2023. It’s perfect to store things like configuration, user data, session data and other app-wide data.
However, it had a significant drawback, in that your database resided in a single location. This made reads potentially slow, as they would have to travel significant distances if the user request originated the other side of the world to your database.
The good news is, this is a problem of the past, with read replicas now being available to everyone. It’s in beta, and you can enable on it a per-database basis in the dashboard.
Before you do though, you need to understand two concepts to ensure your reads perform as you expect:
Sessions are required to ensure sequential consistency. Whenever you run a query, you do so via a session with a unique ID, ensuring that all your queries go to the same replica. This ensures you get consistent results you expect, as the replicas will asynchronously sync their data between themselves. You can either opt to start a session from the primary (ensuring data is the latest) or a replica (where the data may lag behind the primary).
Bookmarks are references to a point within a session, and need to be passed to all your queries after the initial query. This ensures that your query is served by a database that is at least up to date as your last query using this bookmark.
It sounds a little fiddly, and will take some getting used to, but unfortunately with a global platform comes global problems, and this is one of them. It may take some getting used to, and it will be interesting how difficult the sessions and bookmarks are to deal with in a real-world application.
If you want more information, I recommend diving into the docs or reading the full article linked below.
Hyperdrive — MySQL support & Free Tier
Moving onto the service with possibly the coolest name at Cloudflare, we have Hyperdrive, which was first released in September 2023. Hyperdrive is Cloudflare’s service for speeding up your database queries against region-locked databases.
Much like D1 read replication, Hyperdrive is solving somewhat of a unique challenge that Cloudflare faces. With its platform being global, and your Workers being spun up in over 330 cities around the world, what happens when your Worker needs to connect to a database that’s tied to a single location?
In short, it becomes quite slow — especially if you’re executing multiple queries within a single request. That’s because each query will need to go from say Australia to Europe every single time, and additionally, you’ll need to connect to the database each time a Worker is spun up, which is quite often each time a new request comes in as Workers don’t typically hang around for long.
If you’re in a more traditional cloud setup, your compute is probably sitting in the same region as your database, so the latency is actually pretty small between your application and the database. However, there will be high latency from the end user to the actual compute — even for retrieving static assets like images and CSS.
This is where Hyperdrive comes in, which has two primary features:
It acts as a connection pooler, so rather than every instance of your Worker having to connect to the database separately and each time it’s started, Hyperdrive keeps your database connections alive and ready to be used. Considering it takes several round trips to establish a database connection, this is a huge saving on latency.
It has the ability to cache non-mutating queries (e.g. reads) so that for repeated queries, you don’t need to go fetch from your origin database, drastically improving performance by using Cloudflare’s global cache. This is configurable, and you can disable it if you wish.
Ultimately, it’s a no-brainer to use Hyperdrive if you’re connecting to a database that’s locked away in a single region.
As an aside, you’ll want to enable Smart Placement too, which tactically works out the best place to spin up your Worker. By default, the Worker will be spun up as close to the end user as possible. However, if you’re making several database queries, or API calls to externally-hosted systems, Cloudflare can move your Worker to a location that will reduce latency between your Worker and any downstream systems.
Alright back to Hyperdrive, and what’s new for Developer Week?
To start, it now supports MySQL. Up until now, it’s only supported Postgres, so if you have an existing MySQL database you need to connect to, you’re in luck.
In terms of compatibility, it supports MySQL and MySQL-compatible databases (e.g. PlanetScale, Azure, Google Cloud SQL, AWS RDS and Aurora) along with the following database drivers (mysql2, mysql, Drizzle, Kysely).
Secondly, you can now use Hyperdrive on the free tier. I’m a huge fan of adding as much as possible to the free tier, as it allows anyone to try out a service without any commitment.
You get 100,000 database queries per day on the free tier, any beyond that will error out. Just for reference, if you do need more throughput than that, you get unlimited queries on the $5/month Workers Paid plan.
[Hyperdrive explainer | MySQL announcement]
Workflows — Increased Throughput, New APIs & Generally Available
Up next, we’re going to cover one of Cloudflare’s newest products: Workflows. I probably don’t need to explain too much about what they do, as the name is pretty self-explanatory.
In essence, Workflows are Cloudflare’s take on Durable Execution. You can define a Workflow, that has a series of steps, and Cloudflare will execute that Workflow, including recovering from errors and automatially retrying failed steps.
Furthermore, it will keep track of what steps passed on any prior runs, and automatically rehydrate any state needed from steps that successfully completed.
For example, let’s say you have a Workflow that downloads a CSV file on a daily basis and inserts each row into a database. You could do this with a simple scheduled task, but what happens if a database query fails in the middle of the job?
If it’s just a temporary blip, you can retry, but what if your actual database is down, or the host for the CSV file is unavailable? Now you either need something to retry the entire job, or in the case of it failing part-way through, you don’t want to insert duplicate records, so now you need to handle that too, which is a bit of a pain.
All these failure cases are a pain to deal with, but not with Workflows. With Workflows, you could have one step that downloads the CSV and stores it in the Workflow’s state, and then trigger a step for every single row in the CSV to insert it into the database.
If there were 500 rows, and it failed on row 400, the entire Workflow would re-run — but it would know that the first 400 steps succeeded and not re-run those, and pick up where it left off.
Just to preempt, I know 500 rows isn’t a lot and you could likely do one big insert. But what if you’re dealing with 500,000 rows? Going to be a little bit trickier.
Retries and how long to wait between retries is all configurable, and the APIs are really easy to use as they are all written in vanilla JavaScript. You can also have a Workflow pause for a set amount of time too (or a date/time in the future).
In terms of what’s new for Developer Week, my favourite addition is the new waitForEvent API. As soon as I started using Workflows, I wished for a way to pause a Workflow until an event outside my Workflow happened (so much so, I wrote a little hack for it with Durable Objects).
To explain what this enables, let’s say your Workflow takes care of your user onboarding flow. The user signs up, confirms their email, and then we create their account and send them a welcome email.
We don’t want to send that welcome email until the user has confirmed their account, but we do want to send the actual confirm account email. Workflows would be perfect for this, as if the email sending fails to confirm their account, that’s going to be really frustrating — so we can rely on its retries to ensure it’s sent.
The Workflow needs to wait for the user to click the link in the email before sending the welcome email though, so at that point we can make use of the new waitForEvent functionality.
Once the user clicks the link, we can send an “event” to our Workflow and it can resume and send the welcome email — super simple, and super reliable. In terms of sending that event, you can either use a binding from a Worker, or use the Cloudflare REST API.
Alongside the new API, there’s a few more quality of life updates:
Concurrent limits increased: Initially the limit was really low, but as the product has moved through beta, the limits have been raised, and it now stands at a pretty respectable 4,500. This limit will go higher throughout the year, expected to reach 10,000 concurrent workflows by the end of the year.
Improved observability: you can now see CPU time for each Workflow instance in the dashboard.
Vitest support: to enable you to run tests locally and in CI/CD pipelines, there’s now Vitest support for Workflows.
Static Asset Workers — Frameworks Go Generally Available
During Birthday Week last year, Cloudflare started the migration of Pages to Workers with the release of Static Asset Workers in beta. For as long as I can remember, Pages has been the go-to option for hosting static and full-stack websites on Cloudflare.
However, there were always some drawbacks with it, such as not being able to use Durable Objects without creating a separate Worker, and more recently, not having access to Workers Logs.
To solve this problem, the direction from Cloudflare is to move static asset hosting into Workers, in the form of Static Asset Workers. This was confirmed this week with the announcement that no new features would be added to Pages.
If you’re currently hosting sites on Pages, there’s no need to worry about support suddenly disappearing. However, investment, optimisations, and feature work will be focussed solely on Workers when it comes to hosting websites going forward.
Fast forward 7 months, and Static Asset Workers are now generally available, alongside a number of frameworks that it supports:
React Router v7 (Remix)
Astro
Hono
Vue.js
Nuxt
Svelte (SvelteKit)
Qwik
Gatsby
Docusaurus
Angular
This means you can now safely migrate projects that rely on these frameworks from Pages to Workers, and reap all the benefits of wider support for the rest of the Cloudflare developer platform.
If you want to have a go at that migration, there’s a guide available here.
There are some notable frameworks that are not moving to GA, with Next.js and Solid both staying in beta for now. With Next.js notoriously difficult to host on infrastructure outside of Vercel, Cloudflare is working to make OpenNext work seamlessly on Cloudflare with an adapter.
That adapter is now hitting its first major milestone: v1 is available, but still in beta form for now. Most of the Next.js 15 features are supported, including:

Cloudflare will continue iterating on the adapter until it’s ready to hit GA, which I suspect will happen later this year. I really like this initiative as it removes the vendor lock to Vercel that has typically existed for many years around Next.js.
Before moving onto the next section, there’s one more thing worth mentioning around serving sites via Workers, and that’s Vite support on Cloudflare hitting v1, alongside support React Router v7.
[Static Assets GA | OpenNext v1 | Vite v1]
Snippets Are Generally Available
Time for a bit of a history lesson on this one, as it really hits home how far the Cloudflare developer platform has come. When I first heard of Cloudflare Workers, many years ago, they were released as a way to make simple changes to HTTP requests — modify headers, add cookies, things like that.
From memory, it was only possible to edit them via a UI too, which was particularly terrifying, but I honestly might be misremembering that. Either way, it’s fair to say you couldn’t do much with a Worker at that time.
Fast forward to 2025, and as we just covered, Workers can now serve static assets, including a ton of popular frameworks, but they can also be created with any language that supports WebAssembly, they can be APIs, they can be cron jobs, they can consume messages from a Queue, it’s fair to say they are incredibly versatile.
The original use case still exists though, such as making some simple modifications to a HTTP request or response, and for that a Worker is now a little overkill — it can certainly do it, but Snippets now cater for the original purpose that Workers were created for.
If you need to transform headers dynamically, fine-tune caching, rewrite URLs, retry failed requests, replace expired links, throttle suspicious traffic, or validate authentication tokens, that’s where Snippets shine.
So why would you use Snippets over a Worker? That one is easy, it comes down to cost. With a Worker, you pay for the number of requests you handle and the CPU you use. With Snippets, they are free on any paid plan (Pro, Business & Enterprise — they are not currently available on Workers Paid).
If you’re wondering when to use a Worker and when to use a Snippet, Cloudflare’s got you covered:

While not available just yet, later in the year you’ll also be able to access values from Secrets Store from Snippets too.
Super Slurper — 5x Faster With A New Architecture
You’ll perhaps be relieved to know we’re at the end of the recap of Developer Week 2025, with this being the final entry.
If Hyperdrive has the coolest name of any Cloudflare service, then Super Slurper takes the award for the most fun (although its companion, Sippy, is a close second).
Super Slurper is used in combination with R2 to migrate contents from S3-compatible storage on other cloud providers, such as AWS and Google Cloud Storage.
It’s an all-at-once migration, so it will migrate all the objects in one big migration. This is in comparison to Sippy, which does it object-by-object as you request them from an external source.
One of the barriers to entry for moving data across clouds is the difficulty in doing so, but with Super Slurper, it should be a breeze. And better yet, it’ll now be 5x faster to move your data across thanks to a re-architecture of the tool, making use of Workers, Durable Objects and Queues.
If you’re new to the Cloudflare platform, you’ll probably not realise that the vast majority of Cloudflare’s offerings involve “dogfooding” their own products. This is another example of that, with Super Slurper moving from Kubernetes to a native Cloudflare solution.
There’s a ton of detail around how they achieve this in the blog post, which I’d recommend checking out, as I personally really enjoy the technical depth that a lot of Cloudflare’s blog posts go into.
Closing Thoughts
That brings us to the end of my Developer Week recap, and this is definitely one of my favourite Developer Weeks so far.
There’s just so much variety, and you can see that the platform just goes from strength-to-strength, allowing you to build quicker, more efficiently and lets you focus on what you do best: shipping.
I want my developer platform of choice to get in the way as little as possible, while still doing as much of the heavy-lifting as possible. In my view, that’s exactly what Cloudflare does.
I can effortlessly create products and services, with excellent developer experience when developing locally, and push them to production in a few seconds. I also know I can rely on the platform to be stable, and take care of things like scaling and high availability for me.
Above all else, building on the platform is just fun and a joy, I highly recommend you give it a go for yourself — and try out some of the developments announced this week!
Enjoyed the article and want to get a head start developing with Cloudflare? I’ve published a book, Serverless Apps on Cloudflare, that introduces you to all of the platform’s key offerings by guiding you through building a series of applications on Cloudflare.
Lovely recap. The slurper 5x improvement link at end of last section should be updated to https://blog.cloudflare.com/making-super-slurper-five-times-faster/